Introduction
Cet article ne sert strictement à rien. Vous pouvez directement sauter tout en bas pour avoir le fin mot de l'histoire. Ceci dit, si ça vous amuse de lire mes conneries, je vous en empêcherais pas.
Dans le monde du hacking, une branche assez amusante est celle de l'OSINT. Acronyme de Open-Source Intelligence, c'est une spécialité qui consiste à exploiter des données publiquement accessible, sans s'introduire illégalement dans un système d'information. Et ça tombe bien, récolter des données publiquement accessibles, c'est le boulot des moteurs de recherche.
Toutefois, on va exploiter un peu plus loin certains mécanismes proposés par ces moteurs. Et c'est là que l'on rentre dans le dorking, ou l'art de créer des recherches tordues pour récupérer de l'information qui n'était pas si visible que ça. Attachez votre ceinture, c'est parti pour les méandres du Web.
Les index ont un cache
Quelque soit le moteur de recherche, il s'appuie sur un index. Cet index est une gigantesque base de données, qui contient l'ensemble des termes trouvés sur la pages visitées. On parle littéralement de dizaines, centaines voire milliers de To, à tel point qu'aujourd'hui les moteurs de recherche ayant leur propre index sont relativement peu nombreuses. Il n'y en a d'ailleurs que moins d'une dizaine. Cet index sert de base à l'algorithme qui va transformer la requête initiale en résultats de recherche. Sans index, pas de recherche.
Mais là où ça devient intéressant, c'est que cet index a un système de cache. En effet, il est beaucoup trop couteux de mettre à jour cette base de données en temps réel. Il faudrait pour cela mettre une sonde sur chaque page de chaque site qui va récupérer le contenu et mettre à jour si il y a une différence. Ce n'est pas envisageable, même pour des géants du Web comme Google.
Le cache, c'est tout simplement une donnée stockée pour un temps limité dans l'index. Le temps que le robot qui ajoute les pages à l'index revienne dessus et se rende compte que la page a changé. Ça, c'est le premier mécanisme intéressant.
Et aussi du contexte
Quand on fait une recherche quelque part, on a souvent un peu de contexte qui permet de savoir si la page qui nous est présentée est pertinente par rapport à ce que l'on a en tête. C'est très pratique par exemple, si on cherche le terme « Pierre », et que l'on parle du prénom. À partir d'un unique mot, on va pouvoir récupérer quelques mots autour, qui proviennent de l'index du moteur de recherche. Et comme on l'a vu au dessus, cet index a peut-être des trucs en mémoire. ;)
Le cas d'usage, une page inaccessible
Hier soir, mon coloc tombe sur un lien vers un article fumeux sur un site fumeux. C'est un billet de blog, hébergé sur l'espace communautaire de Valeurs Actuelles. Toutefois, même si tout indique que l'article a été posté il y a quelques heures, la page est inaccessible : une 404 laisse penser que le contenu a été supprimé. Mais que contenait cet article pour être indisponible aussi vite ?
Premier réflexe, aller voir si la page a été indexée sur l'Internet Archive : raté. La page n'a pas du rester assez longtemps pour le robot de l'organisation. Mais… Google a eu le temps d'y aller, non ?
N.B. 1 : l'article dont je parle n'a strictement aucun intérêt. Ici je prend l'exemple car c'est un cas d'usage assez intéressant, et surtout qui a bien fonctionné.
N.B. 2 : j'ai repris quelques captures d'écran un peu plus tard, les durées indiquées peuvent ne pas correspondre d'une capture à une autre.
Dorkons, mes bons !
Munis de ces informations, voyons voir ce que l'on peut en faire. Commençons par récupérer un peu de contexte, en donnant à Google l'URL de l'article. J'en profite pour créer un fichier texte dans lequel je vais copier coller mes résultats.
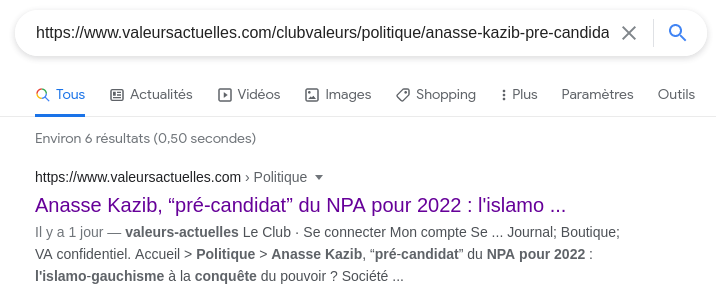
J'ai donc un bout de phrase tirée de l'article. Mais peut-on essayer de tirer les vers du nez de nos amis les moteurs de recherche ? La réponse est oui, absolument.
Toute l'astuce réside dans le fait de réinjecter les extraits obtenus dans une nouvelle requête, en espérant tomber sur un contexte différent, que l'on mettra de coté et avec lequel on répètera l'opération.
La suite, ce n'est que de la patience et un poil de fantaisie. ;)
Du fragment au paragraphe
Afin de cibler au mieux l'article que l'on souhaite récupérer, voici quelques dorks permettant de réduire le champ de recherche :
- Mettre entre guillemets permet de spécifier que l'on veut exactement ce texte
inurl:<termes>indique que l'on veut que lestermessoient présent dans l'URL. On mettra ici un extrait représentatif de l'URL de l'articlesite:<exemple.tld>indique l'on ne veut que des résultats provenant du siteexemple.tld. En indiquant le domaine du journal, on réduit beaucoup le nombre de résultats
Il existe d'autres filtres, mais ces trois là vont déjà permettre de bien avancer.
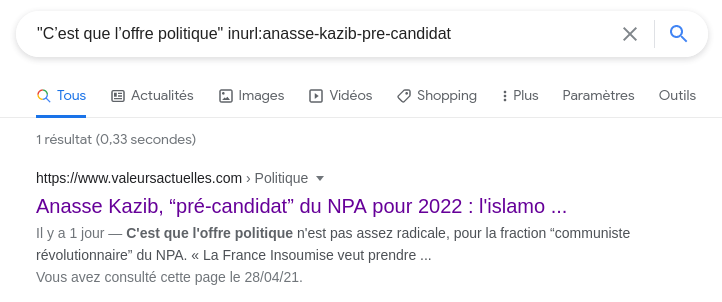
Varier les sources
Au bout d'un moment, il se peut qu'un unique moteur de recherche ne renvoie plus que des extraits que l'on a déjà mis de coté. À ce moment là, une seule solution permet de s'en sortir : utiliser un autre moteur de recherche, ou du moins un autre index.
Et avec un peu de chance, on tombe sur un autre passage, d'autres extraits que l'on ajoutera patiemment à notre collection.
Spéculer, et pas sur les bananes
Il se peut que l'on finisse bloqué, parce que les moteurs de recherche ne veulent plus nous donner plus de contexte que ce que l'on a déjà. Exemple ci-dessous.
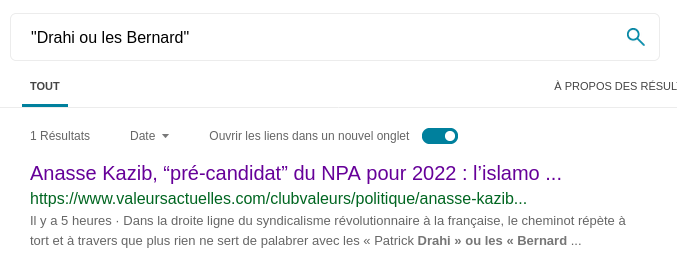
Et bien dans ce cas, spéculons ! En lisant la phrase, on peut se douter que le fameux Bernard est un milliardaire assez connu. En testant deux noms, on se rend compte que le résultat du moteur de recherche est légèrement différent :
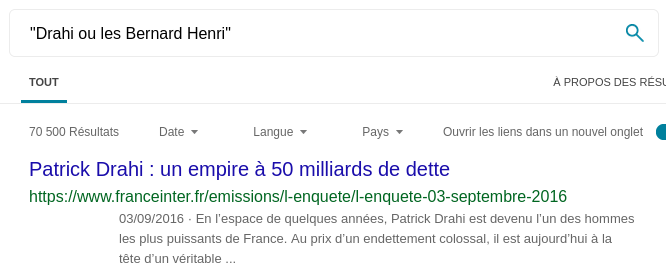
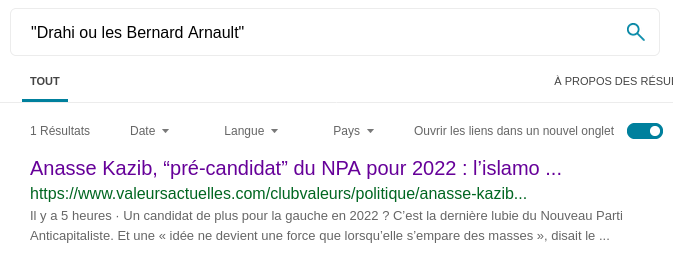
Bien que le contexte ne soit jamais pertinent, cela nous donne un indice de taille. Si Bing a parfaitement identifié l'article qui m'intéresse, c'est que le terme de recherche correspond. Le Bernard dont il est question est donc Bernard Arnault.
Et en cherchant Bernard Arnault sur Google, avec un inurl sur l'article qui va bien, boum du contexte. \o/
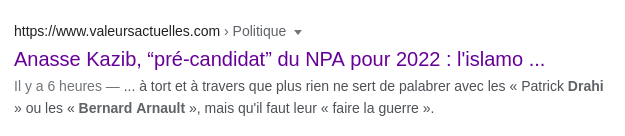
J'ai utilisé cette technique une demi-douzaine de fois au total, avec des résultats mitigés. Il n'est pas toujours évident de tomber parfaitement sur le bon terme.
Organiser le contexte
Au bout d'une heure ou deux (de la patience je disais ?), j'ai pu identifié plusieurs phrases, que je soupçonne être des paragraphes. Malheureusement, je n'ai pas pu récupérer directement l'ordre de ces paragraphes. Et bien dorkons toujours plus !
Un comportement intéressant de Google est que si l'on cherche deux termes bien précis, il va nous sortir un extrait tronqué contenant ces deux termes, dans l'ordre d'apparition de l'article.
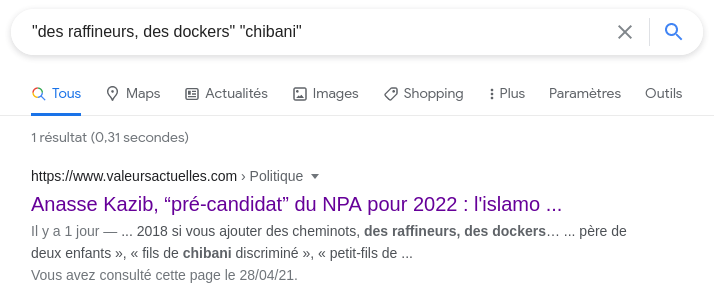
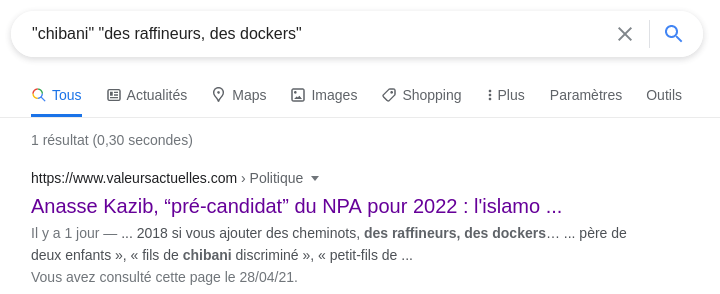
En faisant un peu de dichotomie, on peut facilement retrouver la position d'un paragraphe par rapport à d'autres.
Des résultats suprenants
En trois heures de dorking, j'ai mis en page un article de 1070 mots. Je n'étais pas sûr que certaines parties se suivent directement, donc j'ai mis un marqueur ??? là ou je pensais avoir loupé un passage.
En écrivant cet article, j'ai voulu faire deux choses :
- finir de récupérer des parties louches, en combinant les dorks présentés au dessus ;
- et faire une capture d'écran de la 404 que j'ai évoqué précédemment.
Il se trouve que l'article a entre temps été remis en ligne. Donc je n'ai finalement rien fait. Ce qui est intéressant dans l'histoire, c'est que je peux comparer ma version et celle en ligne. Toutefois, je n'ai aucune garantie que l'article mis en ligne n'ait pas été modifié entre le premier passage des robots indexeurs et le moment où je l'ai récupéré.
Bref, la comparaison est sans équivoque.
Premièrement, je ne me suis jamais trompé dans l'ordre des paragraphes. À chaque fois ils s'enchainaient correctement. Deuxièmement, je ne me suis trompé sur les passages notés ??? qu'une seule fois (j'en avait prévu un alors qu'il n'y en avait pas).
En faisant le total, je n'ai loupé que 9 phrases ou paragraphes, ce qui correspond à 278 mots. Ma version faisant 1070 mots, j'ai donc un taux de correspondance d'environ 75%.
Uniquement en me basant sur le cache des moteurs de recherche grand public et quelques astuces de base, j'ai correctement récupéré 75% d'un article qui a été retiré en moins de quelques heures. Je suis relativement impressionné par ce résultat, je ne m'attendais pas à autant de succès en si peu de temps.
Je finirais juste sur un point intéressant (faites-en ce que vous voulez) : les sites de presse en ligne cachent souvent leurs articles derrière un paywall. Sauf que par soucis de visibilité, le paywall est levé si c'est un robot d'indexation qui passe. ;)
Allez, à la prochaine… o/
Edit : n'ayant pas révisé mes classiques, on me souffle à l'oreille qu'un filtre existe déjà pour récupérer le cache de Google : cache:<url>. J'espère quand même que cet article vous aura fait marrer. ^^
Vous pouvez réagir à cet article en m'envoyant un mail, à blog[@]middleearth[.]fr. Je répondrais avec plaisir :)